Kubelet pod 创建工作流程
Kubelet 是 Kubernetes 的四大组件之一,它维护着 Pod 的整个生命周期,是 Kubernetes 创建 Pod 过程中的最后一个环节。本文将介绍 Kubelet 如何创建 Pod。
Kubelet 的架构
先看一张Kubelet的组件架构图,如下。
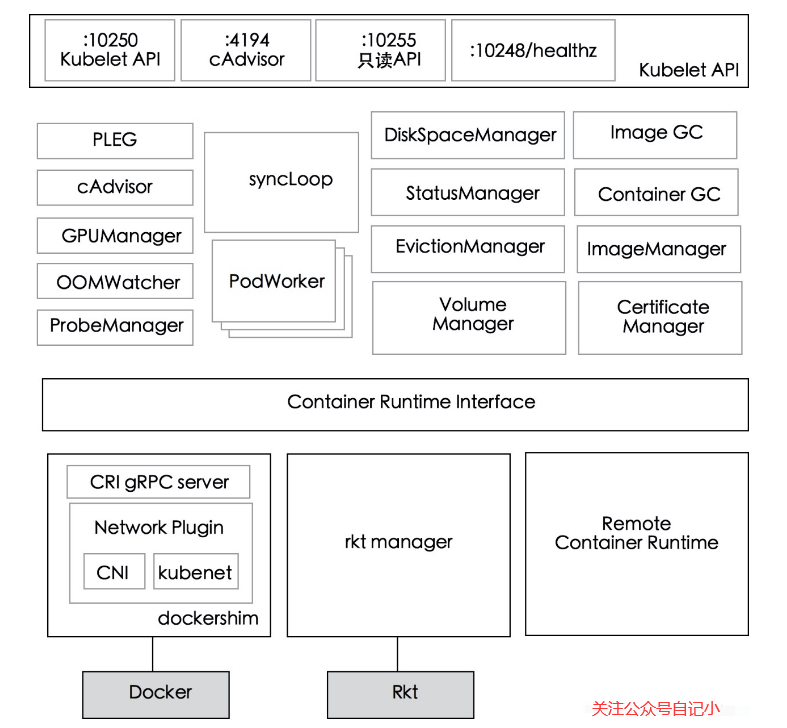
可以看出,Kubelet 主要分为三层:API 层、syncLoop 层、CRI 及以下;API层很好理解,就是对外提供接口的部分;syncLoop层是Kubelet的核心工作层,Kubelet的主要工作就是围绕着这个syncLoop,即控制循环,由生产者和消费者运行;CRI 提供容器和镜像服务的接口,容器在运行时可以作为 CRI 插件访问。CRI 为容器和镜像服务提供接口,在容器运行时可以作为 CRI 插件访问。
让我们看一下syncLoop层的一些重要组件。
- PLEG:调用容器运行时接口获取本节点的容器/沙箱信息,与本地维护的pod缓存进行对比,生成对应的PodLifecycleEvent,然后通过eventChannel发送给Kubelet syncLoop,然后通过定时任务最终达到用户期望的状态。
- CAdvisor:集成在 Kubelet 中的容器监控工具,用于收集本节点和容器的监控信息。
- PodWorkers:注册了多个 pod handler,用于在不同时间处理 pod,包括创建、更新、删除等。
- oomWatcher:系统OOM的监听器,将与CAdvisor模块建立SystemOOM,并通过Watch从CAdvisor接收到OOM信号相关的事件。
- containerGC:负责清理节点上无用的容器,具体的垃圾回收操作由容器运行时实现。
- imageGC:负责节点节点上的图像回收。当存储镜像的本地磁盘空间达到一定阈值时,会触发镜像回收,并删除未被 pod 使用的镜像。
- Managers:包含管理与 Pod 相关的各种资源的各种管理器。每个经理都有自己的角色,并在 SyncLoop 中一起工作。
Kubelet 的工作原理
如上所述,Kubelet 主要围绕 SyncLoop 工作。在 go channel 的帮助下,每个组件监听循环以消费事件或产生 pod 相关的事件到其中,整个控制循环运行事件驱动。这可以用下图表示。
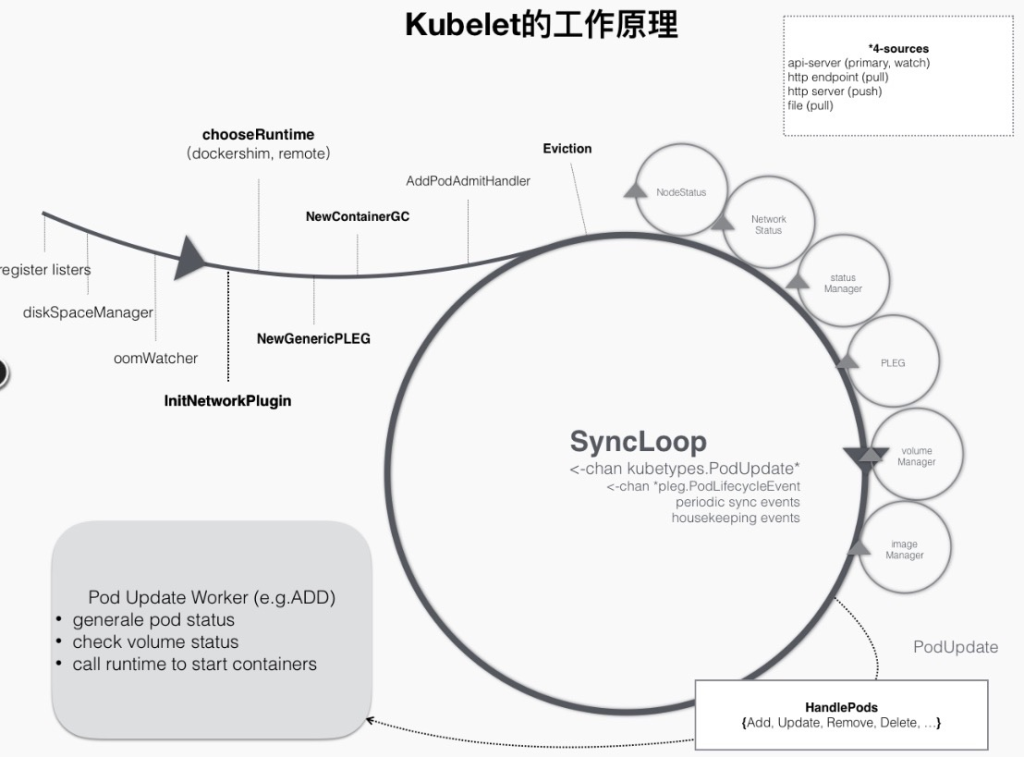
例如,在创建pod的过程中,当一个pod被分派到一个节点时,会触发Kubelet在循环控制中注册的一个handler,比如上图中的HandlePods部分。此时,Kubelet 会检查 Kubelet 内存中的 Pod 的状态,确定是需要创建的 Pod,并在 Handler 中触发 ADD 事件对应的逻辑。
同步循环
让我们看看主循环,SyncLoop。
func (kl *kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
klog.Info("Starting kubelet main sync loop.")
// The syncTicker wakes up Kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
// Responsible for checking limits in resolv.conf
// The limits do not have anything to do with individual pods
// Since this is called in syncLoop, we don't need to call it anywhere else
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
for {
if err := kl.runtimeState.runtimeErrors(); err != nil {
klog.Errorf("skipping pod synchronization - %v", err)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
SyncLoop 启动一个死循环,其中只调用了 syncLoopIteration 方法。syncLoopIteration 遍历所有传入通道并将任何有消息的管道移交给处理程序。
这些渠道包括:
- configCh:该通道的生产者由 kubeDeps 对象中的 PodConfig 子模块提供。该模块将侦听来自文件、http 和 apiserver 的 pod 信息的更改,并在更新来自源的 pod 信息时向该通道生成事件。
- plegCh:该通道的生产者是 pleg 子模块,它会定期向容器运行时查询所有容器的当前状态,如果状态发生变化,就会产生事件到该通道。壯陽藥
li> - syncCh:定期同步最新保存的 Pod 状态。
- livenessManager.Updates():健康检查发现某个 pod 不可用,Kubelet 会根据 pod 的 restartPolicy 自动执行正确的操作。
- houseKeepingCh:用于管家事件的管道,进行 pod 清理。
syncLoopIteration 的代码。
func (kl *kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, Kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.Errorf("Kubelet does not support snapshot update")
default:
klog.Errorf("Invalid event type received: %d.", u.Op)
}
kl.sourcesReady.AddSource(u.Source) case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
// record the most recent time we observed a container start for this pod.
// this lets us selectively invalidate the runtimeCache when processing a delete for this pod
// to make sure we don't miss handling graceful termination for containers we reported as having started.
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
klog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// Sync pods waiting for sync
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
klog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
klog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
klog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
// If the sources aren't ready or volume manager has not yet synced the states,
// skip housekeeping, as we may accidentally delete pods from unready sources.
klog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
klog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
klog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}
创建 Pod 的过程
Kubelet pod 创建过程是由 configCh 中的 ADD 事件触发的,所以这里是 Kubelet 收到 ADD 事件后的主要流程。
处理程序
当 configCh 发生 ADD 事件时,循环会触发 SyncHandler 的 HandlePodAdditions 方法。该方法的流程可以用下面的流程图来描述。
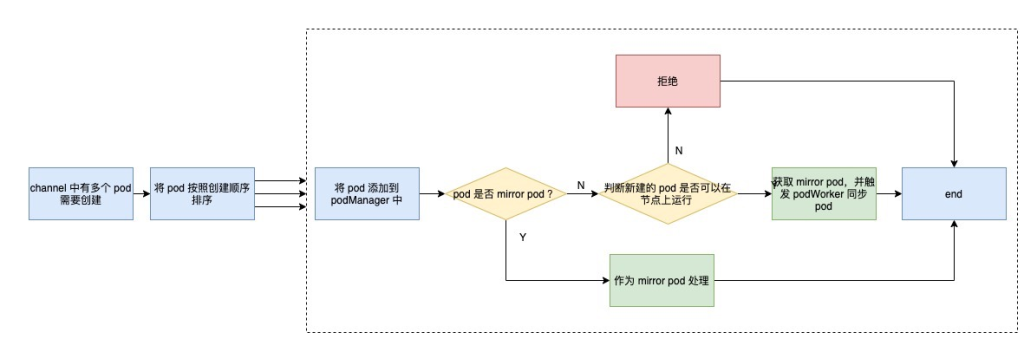
首先,handler 会对所有的 pod 安装创建时间进行排序,然后一一处理。
先将pod添加到podManager中,方便后续操作;然后判断是否为mirror pod,如果是则视为mirror pod,否则视为普通pod,这里是mirror pod的解释。
镜像 pod 是 apiserver 中 kueblet 创建的静态 pod 的副本。由于静态 Pod 由 Kubelet 直接管理,因此 apiserver 不知道静态 Pod 的存在,其生命周期由 Kubelet 直接托管。为了通过 kubectl 命令查看对应的 Pod,以及通过 kubectl logs 命令直接查看静态 Pod 的日志,Kubelet 通过 apiserver 为每个静态 Pod 创建一个镜像 Pod。
下一步就是判断 pod 是否可以在节点上运行,这在 Kubelet 中也称为 pod 访问控制。访问控制主要包括这几个方面:
- 节点是否满足 pod 亲和性规则
- 节点是否有足够的资源分配给 pod
- 节点是使用HostNetwork还是HostIPC,如果是,是否在节点的白名单中
- /proc 挂载目录满足要求
- 是否配置了 pod 以及是否配置了正确的 AppArmor
当所有条件都满足时,最终触发 podWorker 同步 pod。
HandlePodAdditions 对应的代码如下。
func (kl *kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
podWorkers 的工作
接下来,让我们看看 podWorker 是做什么的。podWorker 维护一个名为 podUpdates 的 map,以 pod uid 为 key,每个 pod 有一个 channel;当 pod 有事件时,首先从这个 map 中获取对应的 channel,然后启动一个 goroutine 监听这个 channel,并执行 managePodLoop。另一方面,podWorker 将需要同步的 pod 传递到该通道中。
managePodLoop 收到事件后,会首先从 pod 缓存中获取 pod 的最新状态,以保证当前正在处理的 pod 是最新的;然后调用syncPod方法将同步结果记录在workQueue中,等待下一个定时同步任务。
整个过程如下图所示。

podWorker 中处理 pod 事件的代码。
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options }
}
}
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}
同步Pod
上面的podWorker在managePodLoop中调用的syncPod方法实际上就是Kubelet对象的SyncPod方法,在文件pkg/kubelet/kubelet.go中。
此方法是实际与容器运行时层交互的方法。首先判断是否为kill事件,如果是则直接调用runtime的killPod;然后判断是否可以在节点上运行,也就是上面提到的 Kubelet 访问控制;然后判断CNI插件是否准备好,如果没有,只创建并更新。然后判断pod是否为静态pod,如果是,则创建对应的镜像pod;然后创建需要挂载pod的目录;最后调用运行时的syncPod。
整个过程如下图所示。

Kubelet 的 syncPod 代码如下。为了理解主要流程,我去掉了一些优化代码,有兴趣的可以自己查看源码。
func (kl *kubelet) syncPod(o syncPodOptions) error {
// pull out the required options
pod := o.pod
mirrorPod := o.mirrorPod
podStatus := o.podStatus
updateType := o.updateType
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
...
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
...
runnable := kl.canRunPod(pod)
if !runnable.Admit {
...
}
...
// If the network plugin is not ready, only start the pod if it uses the host network
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
...
if !kl.podIsTerminated(pod) {
...
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
...
}
}
}
// Create Mirror Pod for Static Pod if it doesn't already exist
if kubetypes.IsStaticPod(pod) {
...
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
klog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}
整个创建pod的过程就到了runtime层的syncPod部分,这里就看一下流程。
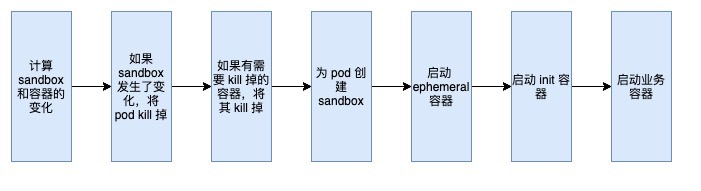
过程很清晰,先计算pod沙箱和容器变化,如果沙箱发生变化,则将pod杀死,然后杀死其相关容器;然后为 pod 创建一个沙箱(无论是需要新建的 pod 还是沙箱已更改并被删除的 pod);后面是启动临时容器、初始化容器和业务容器。
其中,临时容器是 k8s v1.16 的新特性,它临时运行在现有的 Pod 中,以完成用户发起的操作,例如故障排除。
整个代码如下,这里又去掉了一些优化代码来展示主流程。
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
...
}
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
...
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
...
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
...
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
...
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
...
}
klog.V(4).Infof("Created PodSandbox %q for pod %q", podSandboxID, format.Pod(pod))
...
}
...
// Step 5: start ephemeral containers
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
}
// Step 6: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
if err := start("init container", containerStartSpec(container)); err != nil {
return
}
...
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
最后,让我们看看什么是沙盒。在计算机安全领域,沙箱是一种隔离程序以限制不可信进程权限的机制。docker 在容器中使用这种技术,为每个容器创建一个沙箱,定义其 cgroup 和各种命名空间来隔离容器;k8s 中的每个 pod 为 k8s 中的每个 pod 共享一个沙箱,因此同一个 pod 中的所有容器可以互操作并与外界隔离。
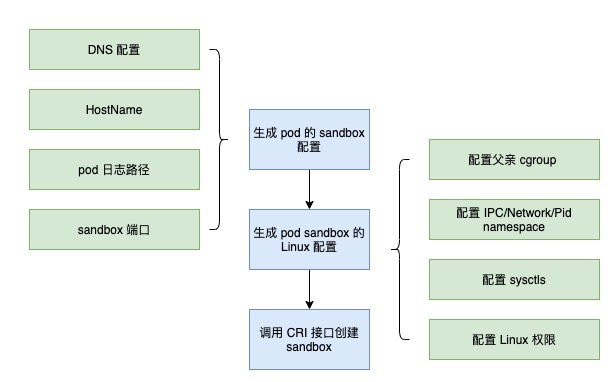
让我们看一下在 Kubelet 中为 Pod 创建沙箱的过程。首先定义Pod的DNS配置、HostName、日志路径、沙盒端口,这些都是Pod中的容器共享的;然后定义pod的linux配置,包括父cgroup、IPC/Network/Pid命名空间、sysctls、Linux权限;一切都配置好之后,那么整个流程如下。
源代码
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
...
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
...
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
...
return podSandBoxID, "", nil
}
func (m *kubeGenericRuntimeManager) generatePodSandboxConfig(pod *v1.Pod, attempt uint32) (*runtimeapi.PodSandboxConfig, error) {
podUID := string(pod.UID)
podSandboxConfig := &runtimeapi.PodSandboxConfig{
Metadata: &runtimeapi.PodSandboxMetadata{
Name: pod.Name,
Namespace: pod.Namespace,
Uid: podUID,
Attempt: attempt,
},
Labels: newPodLabels(pod),
Annotations: newPodAnnotations(pod),
}
dnsConfig, err := m.runtimeHelper.GetPodDNS(pod)
...
podSandboxConfig.DnsConfig = dnsConfig
if !kubecontainer.IsHostNetworkPod(pod) {
podHostname, podDomain, err := m.runtimeHelper.GeneratePodHostNameAndDomain(pod)
podHostname, err = util.GetNodenameForKernel(podHostname, podDomain, pod.Spec.SetHostnameAsFQDN)
podSandboxConfig.Hostname = podHostname
}
logDir := BuildPodLogsDirectory(pod.Namespace, pod.Name, pod.UID)
podSandboxConfig.LogDirectory = logDir
portMappings := []*runtimeapi.PortMapping{}
for _, c := range pod.Spec.Containers {
containerPortMappings := kubecontainer.MakePortMappings(&c)
...
}
if len(portMappings) > 0 {
podSandboxConfig.PortMappings = portMappings
}
lc, err := m.generatePodSandboxLinuxConfig(pod)
...
podSandboxConfig.Linux = lc
return podSandboxConfig, nil
}
// generatePodSandboxLinuxConfig generates LinuxPodSandboxConfig from v1.Pod.
func (m *kubeGenericRuntimeManager) generatePodSandboxLinuxConfig(pod *v1.Pod) (*runtimeapi.LinuxPodSandboxConfig, error) {
cgroupParent := m.runtimeHelper.GetPodCgroupParent(pod)
lc := &runtimeapi.LinuxPodSandboxConfig{
CgroupParent: cgroupParent,
SecurityContext: &runtimeapi.LinuxSandboxSecurityContext{
Privileged: kubecontainer.HasPrivilegedContainer(pod),
SeccompProfilePath: v1.SeccompProfileRuntimeDefault,
},
}
sysctls := make(map[string]string)
if utilfeature.DefaultFeatureGate.Enabled(features.Sysctls) {
if pod.Spec.SecurityContext != nil {
for _, c := range pod.Spec.SecurityContext.Sysctls {
sysctls[c.Name] = c.Value
}
}
}
lc.Sysctls = sysctls
if pod.Spec.SecurityContext != nil {
sc := pod.Spec.SecurityContext
if sc.RunAsUser != nil {
lc.SecurityContext.RunAsUser = &runtimeapi.Int64Value{Value: int64(*sc.RunAsUser)}
}
if sc.RunAsGroup != nil {
lc.SecurityContext.RunAsGroup = &runtimeapi.Int64Value{Value: int64(*sc.RunAsGroup)}
}
lc.SecurityContext.NamespaceOptions = namespacesForPod(pod)
if sc.FSGroup != nil {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(*sc.FSGroup))
}
if groups := m.runtimeHelper.GetExtraSupplementalGroupsForPod(pod); len(groups) > 0 {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, groups...)
}
if sc.SupplementalGroups != nil {
for _, sg := range sc.SupplementalGroups {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(sg))
}
}
if sc.SELinuxOptions != nil {
lc.SecurityContext.SelinuxOptions = &runtimeapi.SELinuxOption{
User: sc.SELinuxOptions.User,
Role: sc.SELinuxOptions.Role,
Type: sc.SELinuxOptions.Type,
Level: sc.SELinuxOptions.Level,
}
}
}
return lc, nil
}
概括
Kubelet 的核心工作围绕着控制循环,它以 Go 的通道为基础,生产者和消费者共同工作,使控制循环工作并达到预期的状态。
